In a quiet but significant leap forward, Microsoft has unveiled Mu, a micro-sized, high-performance language model purpose-built for on-device tasks and it’s already running behind the scenes in the new agent within Windows Settings.
Designed for speed, optimized for edge hardware, and engineered to run entirely on the Neural Processing Unit (NPU) of Copilot+ PCs, Mu is a glimpse into the future of intelligent, responsive, and private AI running locally on your device.
What Is Mu and Why It Matters
At just 330 million parameters, Mu may sound small by today’s LLM standards, but its real-world impact is anything but. It’s the first Microsoft-developed language model designed specifically for low-latency, task-specific inference on edge devices meaning it doesn’t rely on the cloud.
Mu powers the agent in Settings, now available to Windows Insiders on Dev Channel with Copilot+ PCs. This AI agent maps natural language queries like “Turn on dark mode” or “Increase screen brightness” directly to actionable system settings. The result: a more intuitive, accessible way to navigate the complexity of Windows, without lifting a finger or digging through menus.
A Peek Inside Mu’s Architecture
Mu follows a transformer-based encoder–decoder architecture, a departure from the decoder-only models commonly used in generative tasks. This choice wasn’t arbitrary.
By separating input encoding from output generation, Mu eliminates redundant computations. Once the input query is processed by the encoder, the decoder generates output tokens based solely on this fixed representation. This architecture cuts both latency and memory usage crucial for running on NPUs.
Hardware-Aware Optimization: Designed for the Edge
Mu isn’t just software-smart it’s hardware-conscious.
- Parameter Tuning: Layer sizes, tensor shapes, and matrix ops were carefully matched to NPU-specific execution patterns.
- 2/3–1/3 Encoder-Decoder Split: Empirically proven to yield better performance per parameter.
- Weight Sharing: Input and output embeddings share weights, saving memory and improving vocabulary consistency.
- NPU-Optimized Operators: Mu only uses operators supported by the deployment runtime to ensure it runs at peak NPU efficiency.
These choices make Mu not only fast but scalable across diverse edge devices.
Upgrades That Punch Above Its Weight
To maximize performance in a model that’s one-tenth the size of larger peers like Phi-3.5-mini, Mu incorporates several transformer innovations:
- Dual LayerNorm: Applied both before and after sub-layers to stabilize training.
- Rotary Positional Embeddings (RoPE): Supports longer context lengths through better relative position handling.
- Grouped Query Attention (GQA): Reduces attention parameter count while preserving diversity, lowering memory usage and latency.
Training was executed over several phases using A100 GPUs on Azure, starting with high-quality educational corpora and further refined through distillation from Microsoft’s Phi model family ensuring that Mu inherited powerful language capabilities while staying small.
Fine-Tuning for the Settings Agent
When it came time to deploy Mu in the real world, the team focused on a compelling use case: an agent inside Windows Settings.
Changing Windows settings is something users do every day but with hundreds of possible options, navigating them can be tedious. The challenge was to make this process as simple as asking a question.
Initial trials with Phi LoRA delivered strong accuracy, but failed to meet the latency benchmarks for real-time user interaction. That’s when Mu stepped in.
- Training Data Expanded 1300×: From 2,700 to 3.6 million samples, with more than 100 system settings included.
- Synthetic Labeling and Prompt Tuning: Enabled scalable data creation and improved query understanding.
- Noise Injection and Diverse Phrasing: Helped handle ambiguities in user language.
- Performance Outcome: Mu achieved sub-500 millisecond response times while maintaining precision, successfully replacing traditional search for multi-word queries.
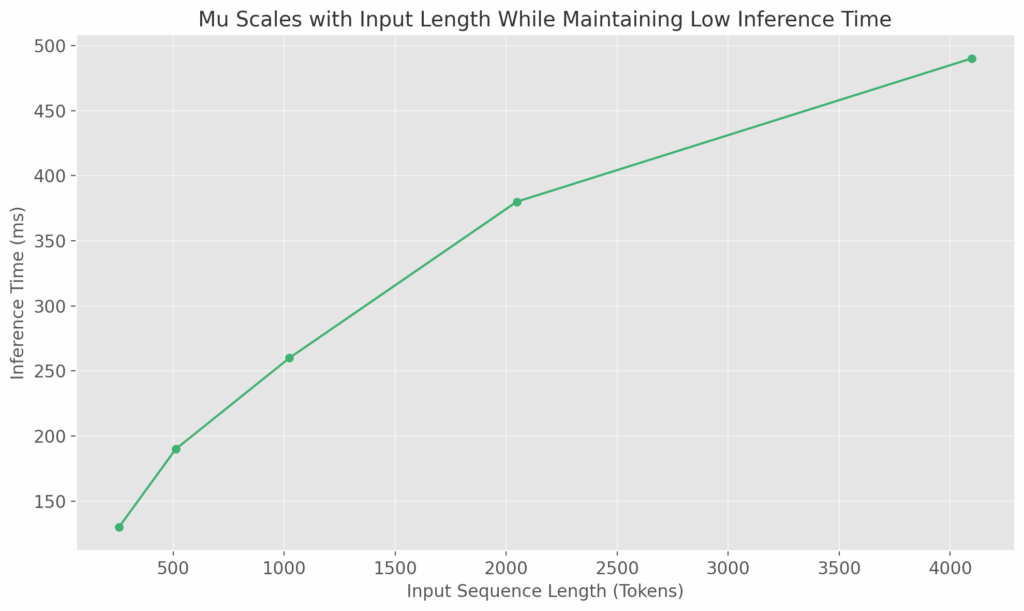
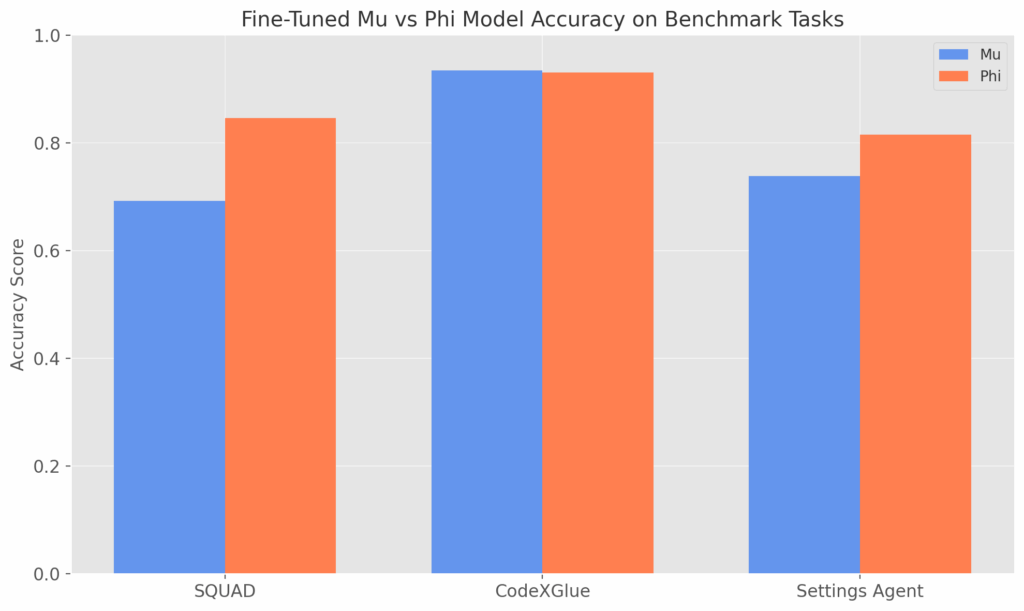
Quantization: Making It Even Leaner
Running Mu on-device wouldn’t be possible without quantization the process of converting floating point weights into smaller integer formats (like 8-bit and 16-bit). Using Post-Training Quantization (PTQ), the team reduced compute and memory usage without retraining the model or sacrificing accuracy.
Collaborating with silicon partners AMD, Intel, and Qualcomm Microsoft ensured these quantized operations ran efficiently across various NPUs. The result: real-world performance of over 200 tokens per second on devices like the Surface Laptop 7.
Navigating Complexity in Windows Settings
One of the most nuanced challenges wasn’t technical it was interpretational.
Simple queries like “Increase brightness” can have multiple valid outputs (primary vs. secondary monitor). To solve this:
- Microsoft prioritized the most common user paths.
- Fine-tuned the model using ambiguous and short-form queries.
- Integrated Mu smartly within the Settings search box:
- Short queries still return classic search results.
- Multi-word queries trigger the agent for accurate, actionable results.
This hybrid approach ensures user intent is honored whether the input is vague or precise.
Mu may be small, but its implications are massive. It represents a shift in how intelligent assistants can function without the cloud, opening the door to AI that’s fast, private, and embedded directly in your device.
From engineering excellence to UX foresight, Mu reflects Microsoft’s growing edge-AI ambitions. In a future where every device will need local intelligence, Mu sets the benchmark for what’s possible in a tenth of the size.